Tri rapide⚓︎
Hors du programme de NSI
Le tri rapide est très utilisé en informatique et son étude est intéressante.
Il n'est toutefois pas mentionné dans les programmes de NSI (ni en Première, ni en Terminale).
Sa mise en œuvre fait de plus appel à la notion de récursivité, notion abordée seulement en classe de Terminale.
Le tri rapide en bref
On choisit une valeur pivot et on partage le tableau en deux parties : les valeurs inférieures au pivot au début, les valeurs supérieures à la fin.
On trie récursivement ces parties.
Présentation visuelle⚓︎
Le tri rapide est un algorithme de tri efficace utilisé dans plusieurs langages de programmation (C et Java par exemple).
A l'instar du tri fusion, le tri rapide suit le modèle « Diviser pour régner ». L'idée générale de l'algorithme est la suivante :
- on choisit une valeur « pivot » dans le tableau et on la garde en mémoire (ici on la place à la fin du tableau),
- on parcourt l'ensemble des valeurs et on effectue des échanges de façon à ce que, à l'issue du parcours, les valeurs inférieures ou égales au pivot soient situées au début du tableau, celles strictement supérieures à la fin,
- la position définitive du pivot est alors la frontière des deux zones. On peut ainsi le placer de façon certaine et réitérer la démarche de façon récursive sur chacune des zones.
Observons le déroulement du parcours, étape aussi appelée partition.
Ce parcours étudie successivement tous les éléments du tableau (variable i).
Lors du parcours on fait en sorte de ramener dans la zone de gauche du tableau les éléments inférieurs ou égaux au pivot. La variable curseur permet de repérer la position d'insertion du prochain élément inférieur au pivot.
Ainsi, à chaque étape du parcours, l'algorithme garantit que tous les éléments d'indices strictement inférieurs à curseur sont inférieurs ou égaux au pivot.
-
État initial

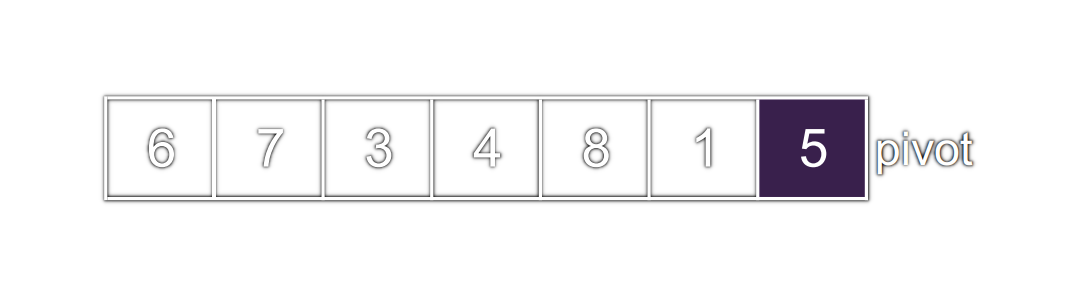
Le pivot est le
5, il est en dernière position.ietcurseursont initialisés à0.
-
1ère étape :
i = 0etcurseur = 0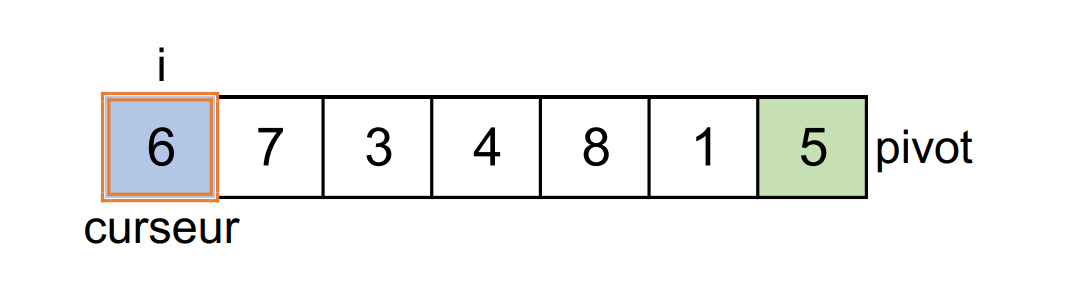

Le
6lu est strictement supérieur au pivot. On ne fait pas d'échange.iaugmente de1.curseurn'est pas modifié.
-
2ème étape :
i = 1etcurseur = 0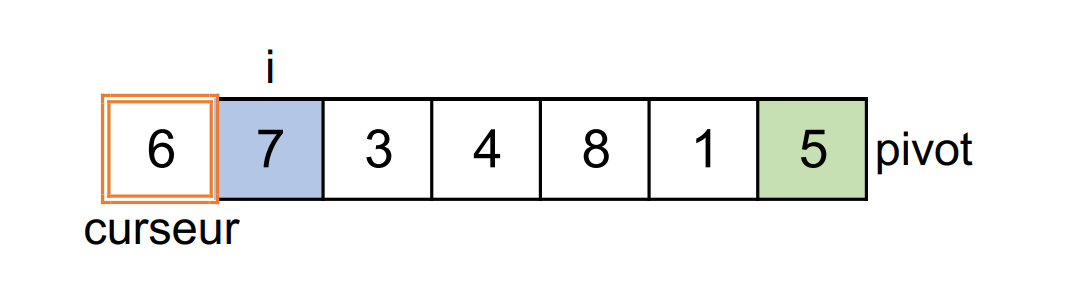

Le
7lu est strictement supérieur au pivot. On ne fait pas d'échange.iaugmente de1.curseurn'est pas modifié.
-
3ème étape :
i = 2etcurseur = 0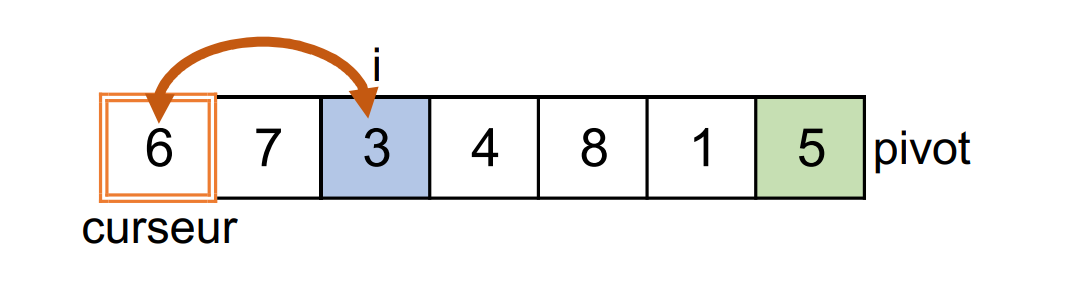
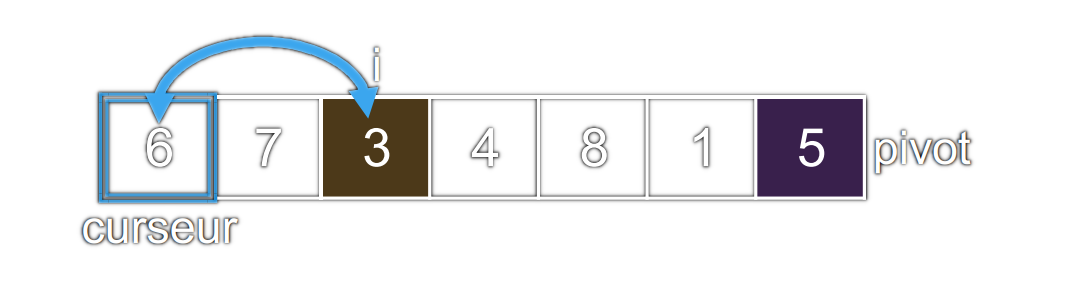
Le
3lu est inférieur ou égal au pivot : on l'échange avec le6situé à la position ducurseur.iaugmente de1.curseuraugmente de1.
-
4ème étape :
i = 3etcurseur = 1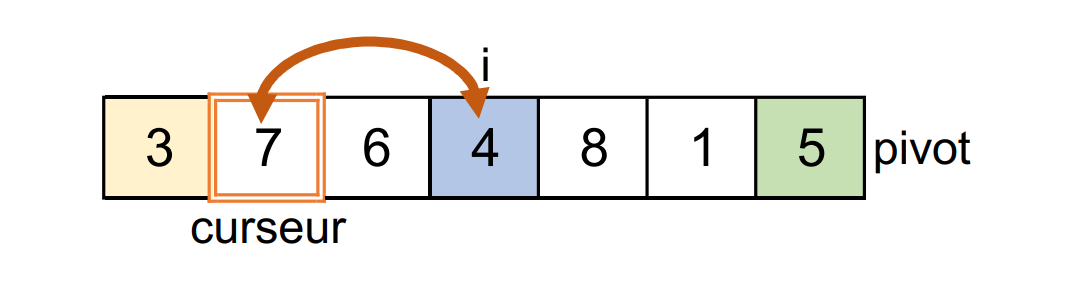
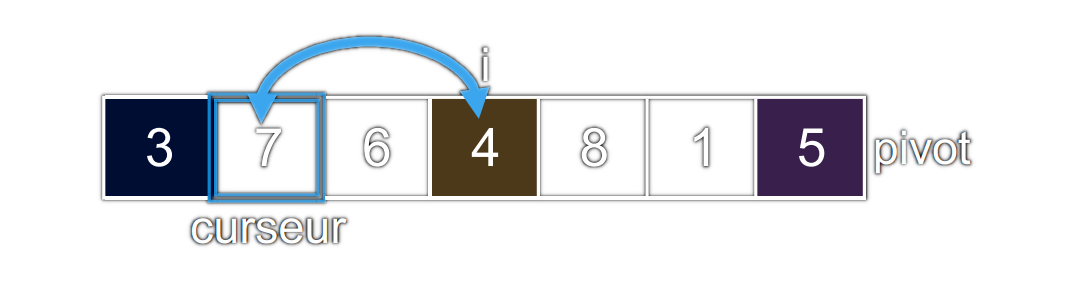
Le
4lu est inférieur ou égal au pivot : on l'échange avec le7situé à la position ducurseur.iaugmente de1.curseuraugmente de1.
-
5ème étape :
i = 4etcurseur = 2
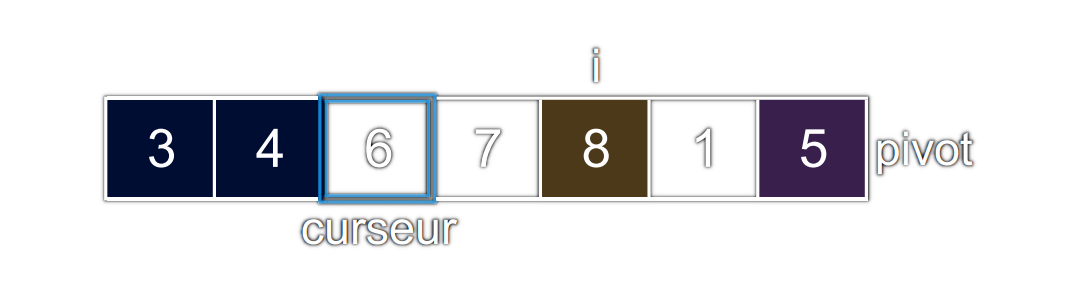
Le
8lu est strictement supérieur au pivot. On ne fait pas d'échange.iaugmente de1.curseurn'est pas modifié.
-
6ème étape :
i = 5etcurseur = 2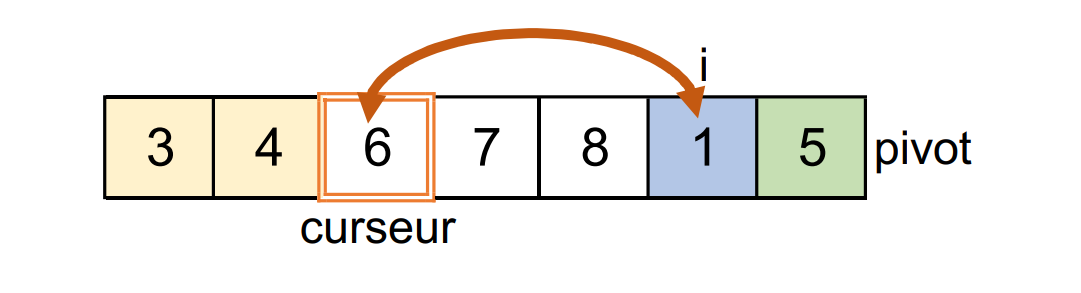
Le
1lu est inférieur ou égal au pivot : on l'échange avec le6situé à la position ducurseur.iaugmente de1.curseuraugmente de1.
-
Fin du parcours :
curseur = 3

En fin de parcours,
curseurvaut3et est égal à la position définitive du pivot.On échange le pivot
5et le7(à la position ducurseur).
-
Partition terminée :
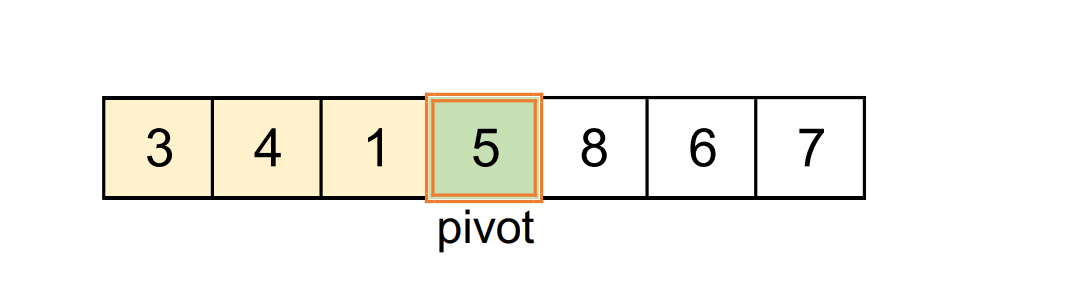
Le pivot est à sa position définitive.
À sa gauche on ne trouve que des valeurs qui lui sont inférieures ou égales. À sa droite que des valeurs strictement supérieures.
Choix du pivot⚓︎
Le choix du pivot est une étape importante.
Il est possible par exemple de toujours choisir le dernier élément du tableau. En moyenne ce choix est intéressant mais il est problématique si le tableau est initialement trié (ou presque trié). Dans ce cas, le choix du dernier élément comme pivot augmente le nombre d'opérations nécessaires et donc le coût de l'algorithme.
Remarque
On peut montrer que le choix du dernier élément comme pivot n'est pas pénalisant si on prend soin de mélanger le tableau avant de le trier. Il est alors peu probable de rencontrer un tableau quasi-trié !
Une autre possibilité est de choisir un pivot aléatoire dans le tableau. Dans ce cas, les tableaux initialement triés n'augmenteront pas sensiblement le coût de l'algorithme.
Dans la suite de cette page on choisira le dernier élément comme pivot afin de simplifier la démarche.
Algorithme⚓︎
On considère un tableau dont on souhaite trier les éléments d'indices compris entre debut (inclus) et fin (exclu).
On choisit comme pivot le dernier élément de la zone à trier. On a donc pivot = tableau[fin - 1].
La phase de partition du tableau consiste alors à parcourir tous les éléments de la zone à trier (sauf le pivot) afin de ramener les valeurs inférieures ou égales au pivot au début de la zone, les valeurs supérieures à la fin.
Pour ce faire on utilise deux indices :
iest l'indice utilisé lors du parcours. Il stocke l'indice de l'élément lu actuellement et évolue entredebut(inclus) etfin - 1(exclu),curseurest l'indice de l'élément qui sera échangé avec l'élément lu si besoin. Au fil du parcours, on est certain que tous les éléments d'indice strictement inférieurs àcurseursont inférieurs ou égaux au pivot.
Ces deux indices sont initialisés à la valeur debut.
Étudions en détail une étape du parcours. On a déjà lu un certain nombre de valeurs et le déroulé de l'algorithme jusqu'à cette étape garantit que i est supérieur ou égal à curseur.
On lit donc la valeur tableau[i] et on la compare à pivot :
- si cette valeur est strictement supérieure au pivot, comme elle est déjà dans la zone des valeurs supérieures (
i >= curseur), on ne la déplace pas ; - si à l'inverse la valeur est inférieure ou égale au pivot, il faut la ramener dans la zone du début du tableau : on échange les valeurs d'indices
ietcurseur. La zone des valeurs inférieures s'est agrandie : on incrémentecurseuren conséquence.
À la fin du parcours, les éléments d'indices strictement inférieurs à curseur sont tous inférieurs ou égaux au pivot. Ceux d'indice supérieurs ou égaux sont strictement supérieurs au pivot. On peut donc placer le pivot à la position curseur en faisant un dernier échange.
Il est ensuite possible de recommencer le tri sur le début du tableau (indice allant de debut inclus à curseur exlcus) et la fin (indices entre curseur + 1 inclus et fin exclu).
Trier votre tableau
Le pseudo-code de cet algorithme est donc le suivant :
Fonction tri_rapide(tableau, début, fin) :
# Cas de base
Si fin - debut < 2 :
Quitter
pivot est égal à tableau[fin - 1]
curseur est égal à début
# Partition du tableau
Pour i allant de debut (inclus) à fin - 1 (exclu):
Si tableau[i] <= pivot:
Échanger les éléments d'indices i et curseur
Incrémenter curseur
# Positionnement définitif du pivot
Échanger les éléments d'indices fin - 1 et curseur
# Appels récursifs
tri_rapide(tableau, début, curseur)
tri_rapide(tableau, curseur + 1, fin)
La fonction tri_rapide
Compléter la fonction tri_rapide prenant en argument un tableau ainsi que deux entiers debut et fin et triant le tableau entre les indices debut (inclus) et fin (exclu) à l'aide du tri rapide.
Solution
def tri_rapide(tableau, debut, fin):
"""
Trie tableau entre les indices
debut (inclus) et fin (exclu)
"""
# Cas de base
if fin - debut < 2:
return
pivot = tableau[fin - 1]
curseur = debut
# Partition du tableau
for i in range(debut, fin - 1):
if tableau[i] <= pivot:
tableau[i], tableau[curseur] = tableau[curseur], tableau[i]
curseur += 1
# Positionnement définitif du pivot
tableau[fin - 1], tableau[curseur] = tableau[curseur], tableau[fin - 1]
# Appels récursifs
tri_rapide(tableau, debut, curseur)
tri_rapide(tableau, curseur + 1, fin)